I Built a Simple, Serverless Content Delivery Mechanism in AWS
21st January, 2021Reading time: 4mMy team and I are in the process of strangling our inherited monolith. Being the ancient, calcified ruin that it is, our crabby behemoth of an app expects all static content (images, scripts, styles, etc) to be hosted on the same machine as the app itself, happily substituting its hostname whenever generating content URLs.
The customer-facing app is replicated across three AWS Elastic Cloud Container (EC2) instances and fronted by an Application Load-Balancer (ALB), which distributes requests between the servers using magic a sophisticated algorithm. What this means is that we have to replicate gigabytes of files between the instances to keep them in sync with each other. After all, we'd hate for a user to be forwarded to an instance with stale content, they might be served a broken page—eek. Not only does this arrangement make it cumbersome to keep the instances up-to-date, but their stateful-ness also makes it difficult to spin up additional ones to meet rising demand during peak periods.
It became clear after our last peak trading period that we had to do something about this, and we quickly narrowed it down to two parts:
- migrating the content to the cloud
- delivering the content to the user
Now, to be completely honest, migrating everything to the cloud turned out to be pretty cut and dried, and often that's exactly what we want in a solution. We turned a complex process into a mundane one—a win in anyone's book, but it wouldn't make for a very interesting read, so let's focus on the second aspect: how do we deliver this content?
You may be thinking that the obvious answer is to use a Content Delivery Network (CDN) backed by a cloud-storage solution—and you may be right about that—but I like learning things the hard way, and I was sure we could do this without changing any URLs on the site. That's right, no risky changes to the monolithic mess. Instead of changing every content URL on the site to point at a CDN, we would simply route all content requests to our new repository at the load-balancer level—our monolith would be none the wiser. (this is okay because the vast majority of our userbase are situated in the UK, so distributed caching isn't needed.)
On that basis, I set about building a Simple, Serverless, Simple Storage Solution Proxy Serviceᵀᴹ (SSSSSSPS). We had to store the files somewhere, and given that we'd already sold our souls to AWS, their Simple Storage Solution (S3) seemed the obvious choice–that it meets our needs was also considered.
My first thought was to position an API Gateway lambda proxy integration behind the load-balancer, but this turned out to be a pretty bad idea because each request–after hitting the ALB–would be redirected away, exiting AWS infrastructure, jump around in the internet for a bit, before finally re-entering the AWS infrastructure at the CDN. Not the best way to deliver content when you're concerned with latency.
I didn't know it at the time, but it's actually possible to target lambda functions in your ALB rules, which was far better suited to this purpose, not least because there is some cleverness under the hood that means the ALB and the lambda are virtually on the same network, so no extraneous HTTP requests.
You can find my SSSSSSPS (I'm committing to the joke) code here. The idea is that a request hitting the load-balancer with a URL like https://my-awesome-website.com/content/images/my-awesome-image.jpg would trigger a rule—matching on '/content/*'—and forward the request to a lambda function, which in turn would retrieve the file from S3 using the path as the key (by replicating the existing folder structure in S3 we would map existing URLs onto it neatly). The lambda, with image in hand, would then set the appropriate headers, format the response as required, and proxy it back through the load-balancer and finally out to the client.
{kind=link}
This turned out to work pretty well, with a couple of cold starts, but nothing to write home about. This was our dev site after all.
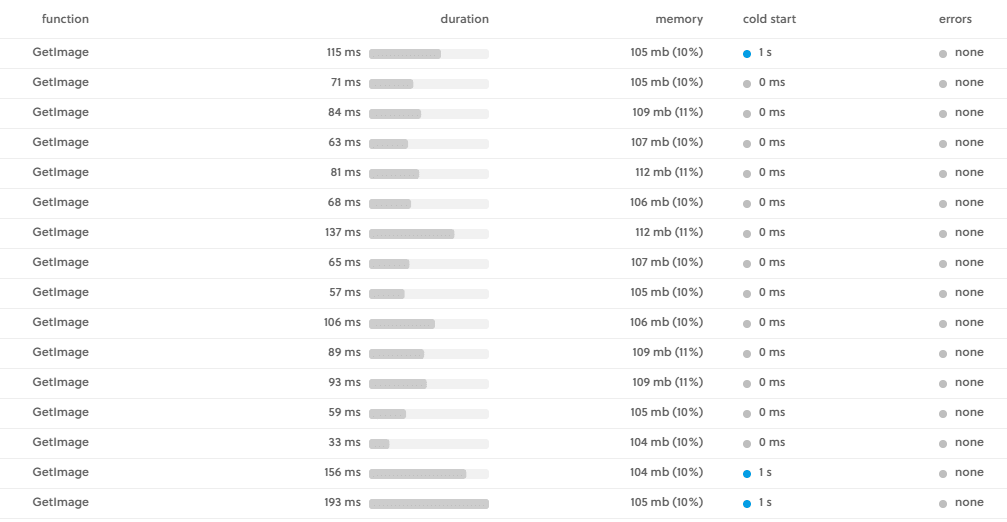
This turned out to be a reasonable solution for a small-scale operation that doesn't need the bells and whistles of a CDN, and/or for anyone wishing to circumvent a grumpy monolith. It could be enhanced with caching if needed, and it would lay the groundwork for features like dynamic image processing using something like Sharp, if you're so inclined.
The guys (and gals) at Serverless Framework actually recommend serving files directly from S3 as an alternative to using a CDN, with the caveat that performance wouldn't be as good for users further away from your bucket. The above solution is simply a variation of this that would have allowed us to modify our site without modifying our site, if you know what I mean.
But truth be told, we didn't pursue this any further because, while it was a useful learning exercise that produced an arguably viable solution, we realised that our needs are likely to grow in the near future, and that maybe those bells and whistles would be nice to have after all.
So, we've come full circle; we're just going to use a CDN backed by a cloud-storage solution.